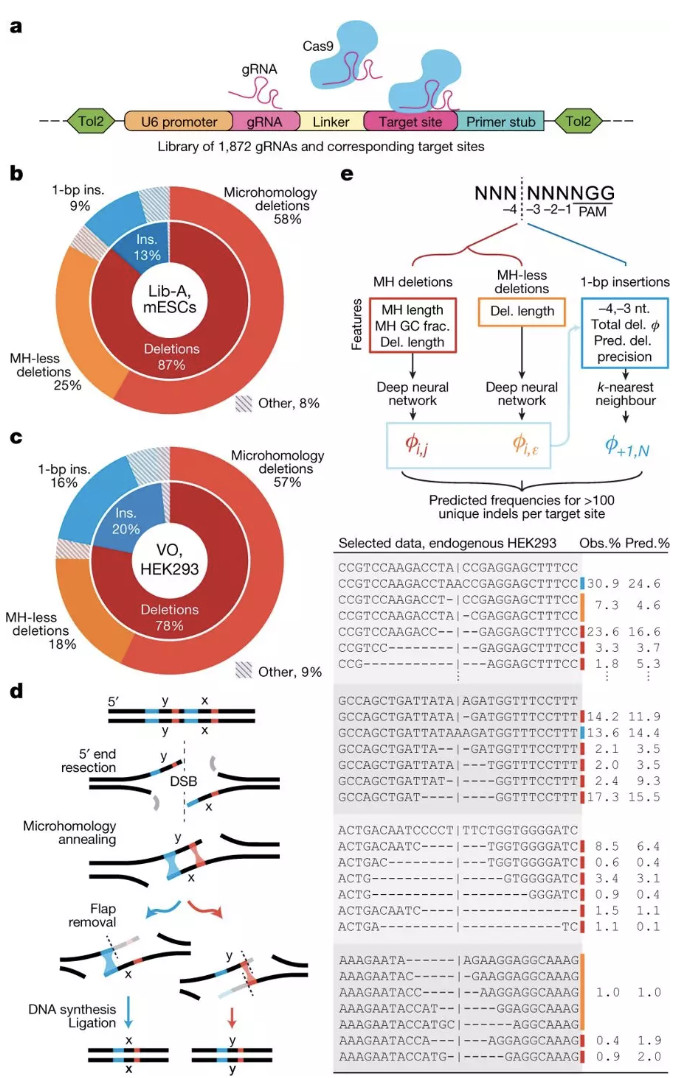
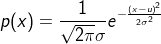《自然》本周在线发表的一篇论文Predictable and precise template-free CRISPR editing of pathogenic variants中报告了一种方法,可以通过机器学习对致病基因变异实现精准且可预测的编辑。这项成果为遗传疾病的研究和潜在疗法提供了新的可能性。
Cas9介导的DNA修复产物的高通量测定有助于inDelphi模型的设计。
虽然CRISPR–Cas9彻底改变了用于研究的基因组编辑技术,但保证这项技术的准确性尤其重要。
CRISPR–Cas9基因组编辑常用DNA“模板”来确保DNA修复的准确性,或将特定的DNA序列导入基因组中。因此,缺少这些模板的DNA修复常被认为不够准确。
现在,美国布列根和妇女医院及哈佛医学院的Richard Sherwood及同事发明了一种用机器学习预测基因组修复结果的方法,实现了精准的无模板Cas9编辑。作者用一个含有近2000对Cas9向导RNA(gRNA)和人体DNA靶点的数据库,训练了一个名为“inDelphi”的机器学习模型。
经该模型识别,5-11%靶向人体基因组的Cas9 gRNA能在超过50%的情况下(被称为“精准-50”)产生单一且可预测的修复结果。inDelphi还能利用无模板Cas9编辑识别并预测出合适的致病基因变异靶标,包括一些曾被认为无法用该方法找到的靶标。
inDelphi准确地预测了几乎所有的编辑结果。
最后,作者通过实验证明,人体细胞中与Hermansky-Pudlak综合征、Menkes病以及家族性高
胆固醇血症这三种疾病有关的近200种致病变异,其编辑和修复的准确性都能达到精准50的标准。
这一研究结果建立了一种实现精准、无模板基因组编辑的方法。
原始出处:
来源: Nature自然科研
版权声明:
本网站所有注明“来源:梅斯医学”或“来源:MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有,非经授权,任何媒体、网站或个人不得转载,授权转载时须注明“来源:梅斯医学”。本网所有转载文章系出于传递更多信息之目的,且明确注明来源和作者,不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。同时转载内容不代表本站立场。
在此留言