梅斯医学MedSci APP
医路相伴,成就大医



梅斯医学MedSci APP
医路相伴,成就大医
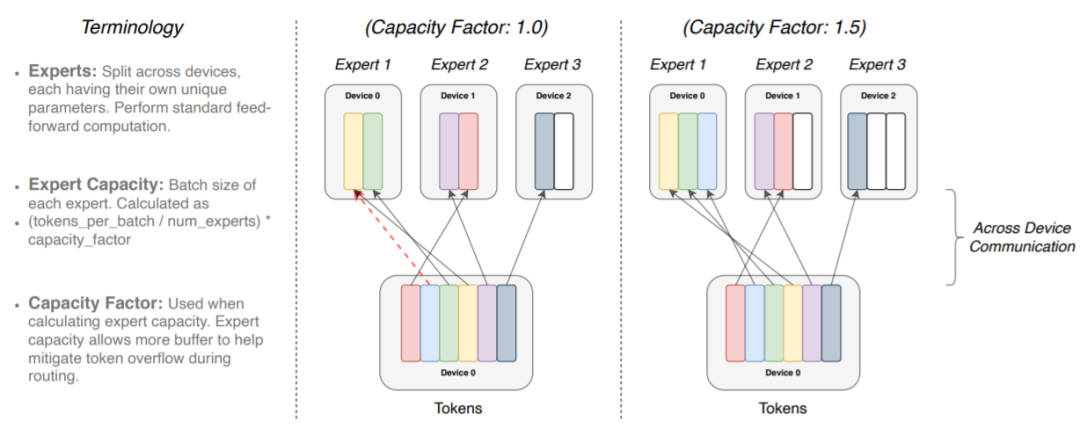
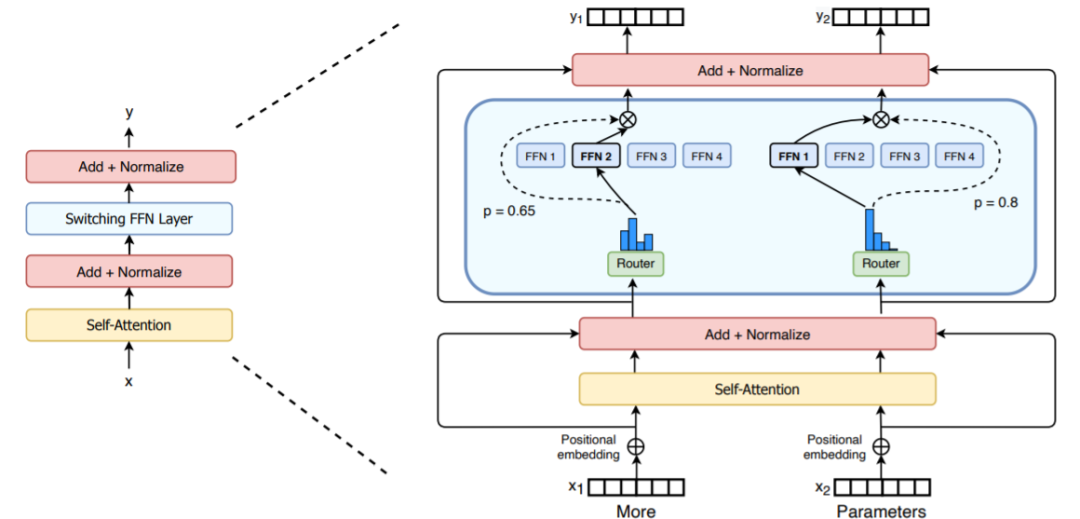
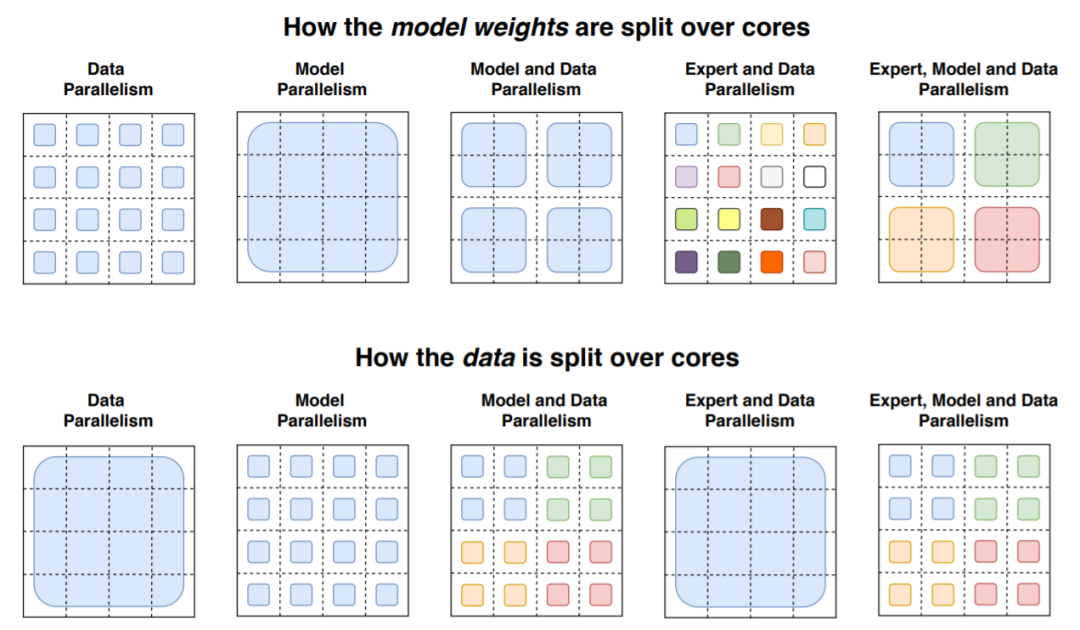
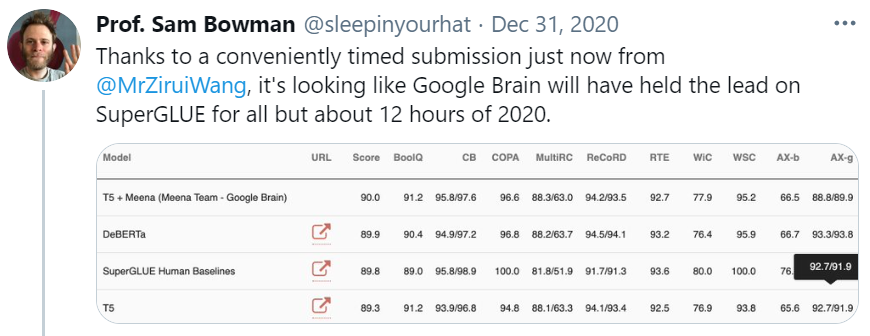
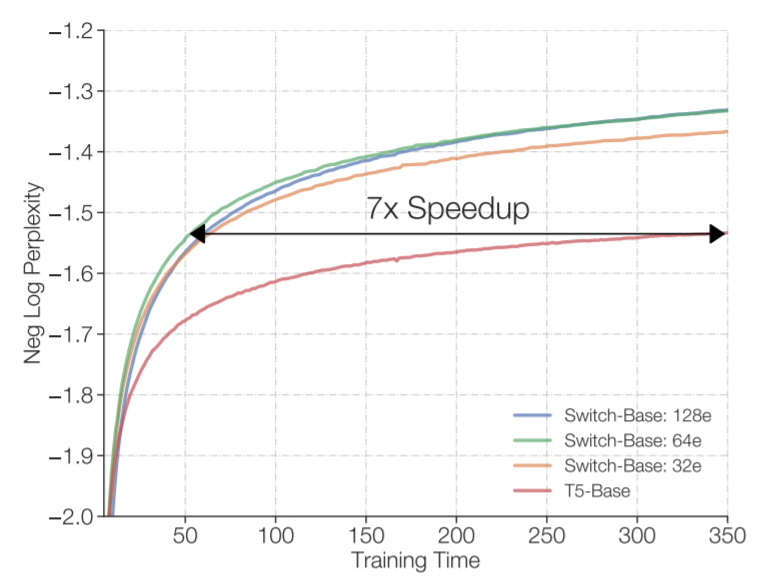
万亿级参数模型Switch Transformer开源了! 距GPT-3问世不到一年的时间,谷歌大脑团队就重磅推出了超级语言模型Switch Transformer,有1.6万亿个参数。 Switch Transformer:迄今最大语言模型 Transformer架构已成为NLP研究的主要深度学习模型。最近的研究工作主要集中于增加这些模型的大小(以参数数量衡量),其结果可能超过人类的表现。 来自OpenAI的团队发现,GPT-3模型的性能确实遵循幂律关系随参数数量扩展。 2021 年初,谷歌发布了一篇题为“Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity”的论文。当时大家并没有重视! 在开发Switch Transformer时,谷歌研究人员力求最大程度地增加参数数量,同时保持每个训练示例和相对少量的数据训练的FLOPS数量不变。 正如研究人员在一篇详细介绍他们研究成果的论文中所指出的,大规模训练是获得强大模型的有效途径。 尽管在大数据集和参数支撑下的简单的架构可以超越一些复杂的算法,然而,高效的大规模训练和密集的计算是关键。 为此,Switch Transformer使用了Mixture of Experts (MoE,混合专家)模型。 不同专家容量因子的路由示例图 MoE由一支研究团队于1991年开发,该团队的成员包括深度学习先驱和Switch Transformer的共同提出者Geoff Hinton,是90年代初首次提出的人工智能模型范式。 MoE会为每个输入的例子选择不同的参数。 多个专家被保留在一个更大的模型中,或者说是专门处理不同任务的模型,针对任何给定的数据,由一个「门控网络」来选择咨询哪些专家。 结果得到一个稀疏激活(sparsely activated)模型——仅使用模型的权值子集,或仅转换模型中输入数据的参数。该参数数量惊人,但计算成本恒定。 Switch Transformer的编码器块图示 研究者利用Mesh-TensorFlow(MTF)库来训练模型,从而利用高效分布式数据和模型并行性。 Switch Transformer的创新之处在于它有效地利用了为密集矩阵乘法设计的硬件,如GPU和谷歌的张量处理单元TPU。 在分布式训练设置中,他们的模型将不同的权重分配到不同的设备上,这样权重就会随着设备数量的增加而增加,但是每个设备却可以管理设备的内存和计算足迹。 数据和权重划分策略图示 此前,谷歌当时的T5组合模型曾在SuperGLUE霸榜。 这一模型在语言模型基准测试榜SuperGLUE上得分超过T5的基础水平,也算是正常发挥。 谷歌研究人员声称,他们的 1.6 万亿参数模型(Switch-C),拥有 2048 名专家,显示出「完全没有训练不稳定性」,其速度相比于T5-XXL模型提升了4倍,比基本的 T5 模型快了7倍。 总的来说,Switch Transformers是一个可扩展的,高效的自然语言学习模型。 通过简化MoE,得到了一个易于理解、易于训练的体系结构,该结构还比同等大小的密集模型具有更大的采样效率。 这些模型在一系列不同的自然语言任务和不同的训练机制中,包括预训练、微调和多任务训练,都表现出色。 这些进步使得使用数千亿到万亿参数训练模型成为可能,相对于密集的T5基准,这些模型可以实现显著的加速。 谷歌已经证明,可以创建创新的模型架构,在不增加计算成本的情况下提高模型性能,这在不久的将来肯定会在数据科学和人工智能社区看到更多。