
梅斯医学MedSci APP
医路相伴,成就大医



梅斯医学MedSci APP
医路相伴,成就大医
随着测序技术的进步与发展,生物医学领域获得的组学数据正呈爆发式增长。不同的研究项目和研究手段,产生了以基因组学、转录组学、蛋白质组学和代谢组学为大类的多种组学数据。但是单独一种组学的数据只是从单一角度解释生物学问题,将多组学数据互补整合起来可以增深我们对生物的全面认识。为此,科学家已经开发了多种方法,例如多核学习、贝叶斯共识聚类、基于机器学习(ML)的降维、相似性网络融合和深度学习(DL)方法等。 文章发表在Genome Biology上 主要研究内容
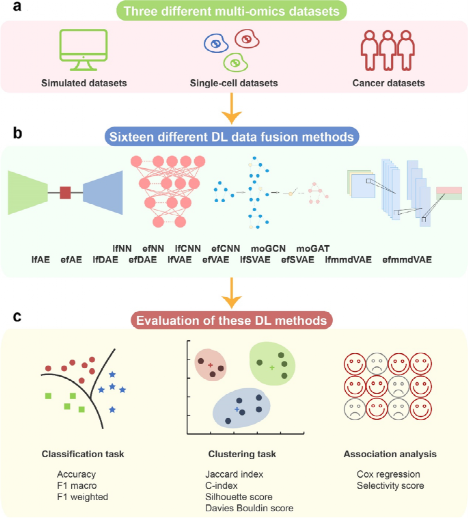
图1. 测试评估流程图
1.在模拟数据集上计算与评估
研究人员使用InterSIM CRAN包生成了模拟多组学数据,并使用基于深度学习的多组学算法进行计算与评估。这些模拟数据包括DNA甲基化、mRNA基因表达和蛋白质表达等数据。通过区分有监督方法和无监督方法,并通过一定的指标进行评价,最终获得分析的结果。
2.在单细胞多组学数据集上计算与评估
3.在癌症数据集上进行计算与评估
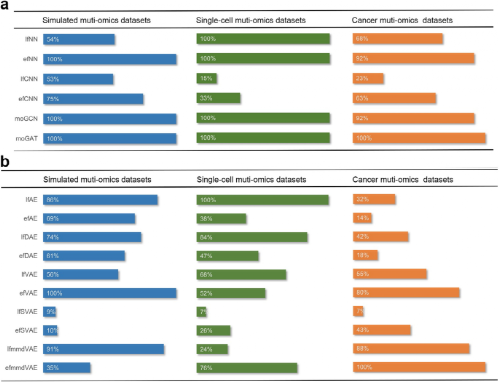
图2. 基于深度学习计算方法的测试与评价
主要研究结果
在模拟多组学数据集上进行评估时,大多数监督方法在分类任务中表现出良好的性能,尤其是efNN、moGCN和moGAT。两种基于卷积神经网络(CNN)的方法(efCNN和lfCNN)效果较差,表明在输入上使用带有一维卷积层的CNN可能不适合多组学数据融合。对于聚类分析,efAE、lfmmdVAE和efVAE表现最好。与模拟数据集的结果类似,moGCN和moGAT在单细胞数据集的分类任务上表现非常出色。对于单细胞数据集上聚类性能的评价,efmmdVAE和lfAE是最有效的方法。在癌症数据集中,moGAT在分类任务上仍然优于其他监督方法。在评估聚类性能时,efmmdVAE、efVAE和lfmmdVAE在大多数场景下取得了较优的结果。在嵌入生存或临床注释等信息时,评估组学数据与之的关联,lfVAE和lfSVAE是最有效的。因此,对于需要嵌入额外信息的研究,lfVAE和lfSVAE值得优先考虑。
基于上述结果,为了使评价更加直观,研究人员定义了一个统一的分数,并根据统一的分数对这些深度学习算法进行排序。如图2所示,对于分类任务moGAT在三个不同的多组学数据集上排名第一。对于聚类任务,efVAE、lfmmdVAE和lfAE是模拟数据集上排名前三的算法。lfAE、lfDAE和efmmdVAE是针对单细胞数据集的前三种算法。efmmdVAE、lfmmdVAE和efVAE是针对癌症数据集的前三种算法。
结 语
越来越多的证据表明,多组学数据融合分析在广泛的生物医学研究中发挥着重要作用。该研究系统地评估了16种基于深度学习的算法,结果表明,moGAT具有最佳的数据分类能力;efmmdVAE、 efVAE以及lfmmdVAE具有最佳的数据聚类能力。
总体而言,专注于分类任务的研究人员应优先考虑基于GNN的算法,基于GNN的算法可将多组学数据构建成相似网络,样本之间的相关性可以通过相似性网络捕获。因此,研究人员可以有效地利用数据的组学特征和几何结构,提高分类性能。在关注聚类任务时,可优先考虑efmmdVAE、efVAE和lfmmdVAE,这三种算法在所有不同的基准测试中具有最有效和最一致的表现。
参考资料:
Leng, D., Zheng, L., Wen, Y. et al. A benchmark study of deep learning-based multi-omics data fusion methods for cancer. Genome Biol 23, 171 (2022).
https://genomebiology.biomedcentral.com/articles/10.1186/s13059-022-02739-2
Sci Adv:王泽峰团队发现癌症中广泛存在一种全新的长度依赖性剪接失调
![]() 0
2022-08-19
点击查看
0
2022-08-19
点击查看
柳叶刀:吸烟、喝酒和肥胖,导致全球一半的癌症死亡
![]() 0
2022-08-20
点击查看
0
2022-08-20
点击查看
Cancer:为什么是你得癌症,而非别人?这些风险因素需自查
![]() 0
2022-08-21
点击查看
0
2022-08-21
点击查看
柳叶刀重磅:想减少一半癌症死亡,避开这些风险因素即可!
![]() 0
2022-08-24
点击查看
0
2022-08-24
点击查看

JAMA子刊:27万人随访12年分析:运动可降心血管、癌症风险!但做哪种/做多少最好?大有讲究!
![]() 0
2022-08-27
点击查看
0
2022-08-27
点击查看

ESC 2022:预防癌症治疗引起的心脏问题的建议今天发布
![]() 0
2022-08-28
点击查看
0
2022-08-28
点击查看

